
How Neural Networks Learn
A 5 minute Breakdown of How Neural Networks Actually Work

Hey 👋! I’m Arjun, a 16 year-old working in the intersection of using AI to improve cancer treatments and diagnostics. Welcome to import learn ai: a one-stop shop for everything AI/ML/DL. Enjoy!
The explosion of AI in the last few years has changed the course of humanity forever. New models like ChatGPT, GPT-4, and Med-PaLM-2 are capable of things we couldn’t imagine just a decade ago.
But, how do these models even work? The answer: Neural Networks.
Neural Networks are the Brain of AI

Neural Networks are Function Approximators
At a high-level, neural networks act as functions.
If we know the function and have it defined, it is possible to calculate any output given an input. In other words, for any input, there exists an output.

Let’s say we are given some data that contains inputs and outputs, but not a function. Think of these as points on a graph that are not connected.
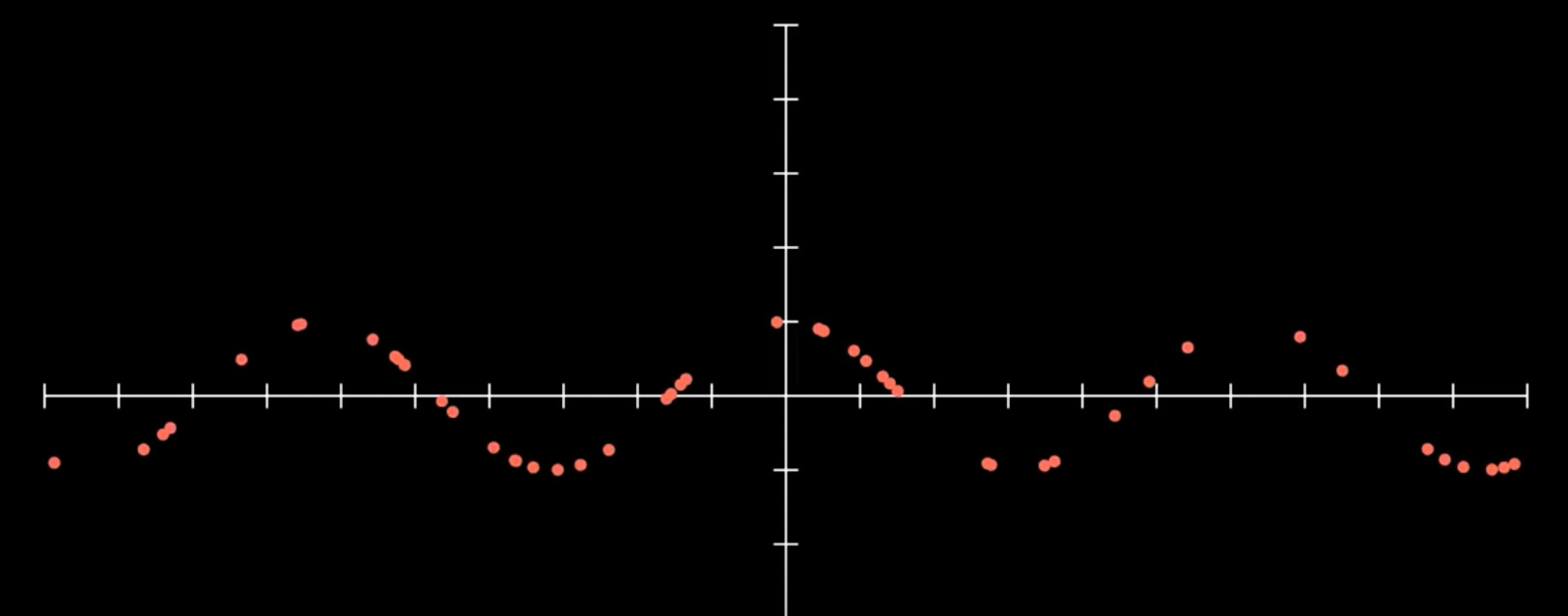
With this information, we could create a function that would model these inputs and outputs. And, we could use that function to calculate outputs for inputs not included in our dataset. Hence, a prediction.
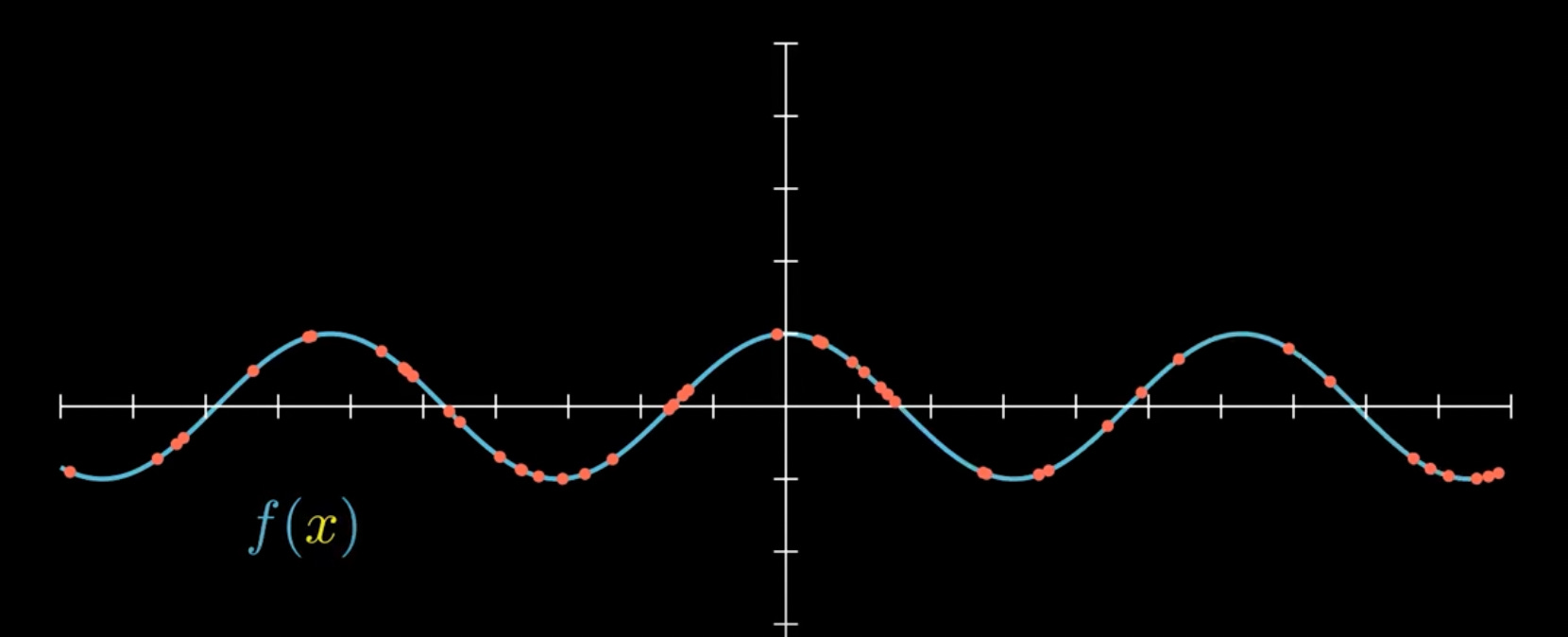
This function approximator is a neural network.
So neural networks, more precisely are function approximators.
A Neural Network is Modelled LooselyAfter the Brain
When you hear the term “Neural Networks,” the first thing that probably pops into your mind is the brain. It turns out, Neural Networks are loosely modelled after the brain.

Essentially, neural networks are a network of neurons. For now, we will define neurons as something that can store a number between 0 and 1. This value, between 0 and 1 is called an Activation.
All of the neurons are densely interconnected, are categorized into layers. Even basic neural networks can have thousands or even millions of these neurons.
Different layers in the network have different functions, but collectively, act as a function. In almost every neural network there are 3 primary layers:
Input Layer: This is where the inputs are fed into. Inputs are usually labeled data that the machine must classify.
Hidden Layers: These layers perform different functions at the same time.
Output Layer: The activation of the neuron in the output layer corresponds to how much confidence the system has in its prediction.

Each neuron in every later takes in outputs of the previous layer as its input and spits out a computed output (activation) that will be sent to the next neuron(s).
Weights, Biases, and Activations
For each incoming connection, a neuron will assign a weight and bias.
Weights are just numbers that determine the strength of the connections between the neurons. Every weight is multiplied by the activation of the previous neuron, which adjusts in the incoming data. During the training of a neural network, the weights are adjusted so there is less deviation from the network’s predicted values and the actual.
Biases are just constants that are added/subtracted to the weighted sum of the network.
To summarize, weights are multiplied by activations and this sum is added/subtracted to the bias.

But wait, there’s more.
When this sum is plotted on a number line, any number (activation) can come out. So how do neural networks fit these activations between 0 and 1?
Neural Networks make use of an activation function. This is usually a logistic curve that squishes all of the outputs to a value between 0 and 1. In the case of a logistic curve called “the sigmoid function” visualized below, our weighted sum is multiplied by σ.

The function showed above is a sigmoid function, but a newer activation function called ReLU (which serves a similar purpose) is more efficient.

Mathematically, the computation for each neuron to the next is as follows:
 — Part 1 | by Kiprono Elijah Koech | Towards Data Science")
If the output of a neuron is below a certain value, the neuron does not pass data to the next layer. If the output is greater than that certain value (minimum value), the neuron “fires” or sends the number off to the next interconnected layer.
Training a Neural Network is an Iterative Process
At the beginning of training, all of the parameters a neural network contains are randomized. Through many iterations called epochs, these parameters are updated to match the training data as best as possible.
Remember neural networks are approximation functions; they try to predict labels to data that’s fed into it.
Neural Networks Learn Through Gradient Descent and Backpropagation
Understanding how neural networks actually learn boils down to 2 things you need to know:
The Goal of Neural Networks is to Minimize The Cost Function
The Cost Function is a measure of how much the predictions a neural network makes match the expected predictions. Essentially, it’s a quantification of the error between the predicted and expected values.
So, the smaller the cost function, the better our neural network.
A process called Gradient Descent used to optimize the cost function. Without getting into too much math, it does this by numerically estimating where a function outputs its lowest values.
Over many iterations, steps proportional to the negative of the gradient (moves in the opposite direction of the positive gradient) are taken. Derviatives (which find the slope of a point or instant on the gradient) are calculated to determine the direction to take these steps.

Think of it as a ball rolling down a hill; it will ultimately lead to the lowest point on the hill due to gravity. Gradient Descent works in the same way!

Backpropagation Adjusts the Weights During Training
Backpropagation is a complicated word for fine-tuning the weights established based on the error rate from the previous iteration. That was a mouthful. Let me explain.
Since the weights are randomized at the beginning of training, backpropagation changes them so the outputs more accurately reflect the data. Fine-tuning these weights will lead lower rates and hence, more accurate predictions.
For those experienced in calculus, backpropagation calculates the gradients (minimum value of the cost function) using the chain rule. These weights are shifted based on this calculation.

And That’s It. That’s How Neural Networks Learn.
If you understood everything mentioned, you’ve officially got a solid understanding of how neural networks work.
If you enjoyed this article, I would appreciate you subscribing for more machine learning content to pop up in your inbox! ‘Till next time!
References
[1] But what is a neural network? | Chapter 1, Deep learning